PURPOSE
In this post, I’ll be taking the query at the end of Intro to Log Analytics, converting it to the new InsightsMetric format and walking through the more complex KQL language.
Here is what we’ll be starting with:
Perf
| where CounterName has '% free space' and Computer in ((Heartbeat | where OSType has 'windows' | distinct Computer))
| where InstanceName !has '_total' and InstanceName !contains 'harddisk' and InstanceName !has 'C:'
| project Computer, InstanceName, CounterValue
| summarize PercentFree=avg(CounterValue) by Computer, InstanceName
| project Computer, InstanceName, PercentFree
| join (Perf
| where CounterName has 'free megabytes' and Computer in ((Heartbeat | where OSType has 'windows' | distinct Computer))
) on InstanceName, Computer
| where InstanceName !has '_total' and InstanceName !contains 'harddisk' and InstanceName !has 'C:'
| project Computer, InstanceName, CounterValue, PercentFree
| summarize averageMegabytesFree=avg(CounterValue) by Computer, InstanceName, PercentFree
| project Computer, InstanceName, averageMegabytesFree, PercentFree
The key items to point out here are project and join. I’ll get into those as we go along. You’ll also notice the importance of moving to the new Azure Monitor for Virtual Machines. Before, you needed separate queries for both Windows and Linux on most things but with the new platform, that’s no longer a problem. If you’re writing these for alerting purposes, this should be interesting.
WALKTHROUGH
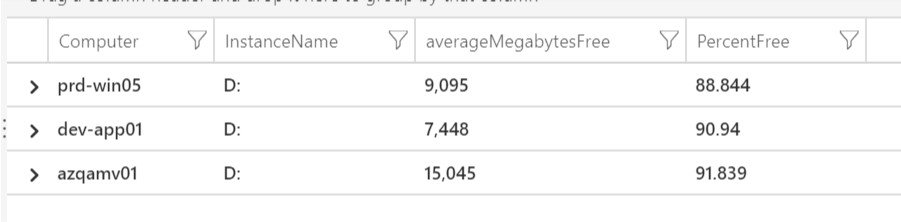
Going back to the first post on this topic we must understand what data is contained in the table. Once we know what we’re looking for, we can then structure the query to model a view. If you haven’t noticed in the query above, this is a disk query that is filtering data first on Windows computers, calculating average percent free disk space and then joining that data against Windows computers free megabytes of disk space. Why would you do this? While it’s really easy to see either of these metric separately, it’s also very important to view them together. If you have a disk that has less than 20% free space that may not be a problem if it’s on a 4TB volume. On the other hand, with the same situation it may have more of an impact if the volume is only 30GB. It’s also important to realize this query ignores the C: drive because that’s the OS drive and is probably going to be viewed separately.
I’ll first explain how this query works then I’ll show what it looks like in the new platform.
Perf
| where CounterName has '% free space' and Computer in ((Heartbeat | where OSType has 'windows' | distinct Computer))
| where InstanceName !has '_total' and InstanceName !contains 'harddisk' and InstanceName !has 'C:'
As you can see, we’re looking at the Perf log table. In that table, we want to first filter on CounterName and then OS Type. Because there isn’t an OS type column in the Perf table, we are taking the Computer column and matching that columns data with data in the Heartbeat table where OSType matches “Windows”. Then, we want to filter out _total, harddisk and C:. This will leave you with all other drive letters only.
!has and has If you haven’t seen/used this, it’s really powerful because it will match, case-insensitive, on the exact string. The ! means not.
!contains and contains Also very powerful. This will search for a match on the a string using the value provided. If you don’t know the exact value like in has, use this.
Why not == or != ? Both are case sensitive and must be exact. You’ll find that query performance is much improved using has and contains variants.
In the next part of the query we are projecting and summarizing. The project only returns table columns that we want to work with. This is a great way to trim data that’s returned which only makes your query faster.
| project Computer, InstanceName, CounterValue
| summarize PercentFree=avg(CounterValue) by Computer, InstanceName
| project Computer, InstanceName, PercentFree
Before we calculate the average, we want to filter only on the data we want to work with: Computer, InstanceName (drive letter) and CounterValue (% free space). As we saw in the previous posts example, we are calculating the average avg() of the CounterValue. This is exactly like calcuating the average percent CPU usage. After the calculation, another project is used to create a brand new table with the new value PercentFree (from the average of the % free space CounterValue).
This next section is really cool because we’re joining the same table together EXCEPT we’re using a different CounterName. This is where we can create the data necessary to build a view that fits our needs of looking at Computer, Drive Letter, % Free Space and Used Space.
| join (Perf
| where CounterName has 'free megabytes' and Computer in ((Heartbeat | where OSType has 'windows' | distinct Computer))
) on InstanceName, Computer
The join feature is awesome all by itself and could probably be a post on it’s own. This is the simplest form of join you can do. For more complex joining, I encourage a look into the documentation. In this situation, we are taking our projection and joining the results of the joined query where the Computer and InstanceName match in both tables. If there isn’t a match on Computer and InstanceName, it is omitted. If you stop here and look at the output, it’s a mess. The next part will clean that up by filtering and calculating free megabytes on each drive letter.
| where InstanceName !has '_total' and InstanceName !contains 'harddisk' and InstanceName !has 'C:'
| project Computer, InstanceName, CounterValue, PercentFree
| summarize averageMegabytesFree=avg(CounterValue) by Computer, InstanceName, PercentFree
| project Computer, InstanceName, averageMegabytesFree, PercentFree
As before, the first line is identical to the top half of the query. The second line adds the newly created value PercentFree to the joined data containing free megabytes. Now, we have a table that shows average % free space against free megabytes. The next line calculates the average free megabytes, just as before on free space. And lastly, a final projection showing the data all together.
Now that we know what the query is doing, it can be adapted to work in the new InsightsMetrics table. Here is what the new query would look like. Notice the key differences? No longer do you need to filter on OS type and now you need to extract the drive letter details from the tag values. The query seems more complex but in form, it’s doing the same thing.
InsightsMetrics
| where Namespace has "logicaldisk" and Name has "freespacepercentage"
| extend MountValue=parse_json(Tags)
| extend Mount=MountValue.["vm.azm.ms/mountId"]
| project Computer, Mount, round(Val)
| summarize ["Average % Free Space"]=avg(Val) by Computer, tostring(Mount)
| join (InsightsMetrics
| where Namespace has "logicaldisk" and Name has "freespacemb"
| extend MountValue=parse_json(Tags)
| extend Mount=MountValue.["vm.azm.ms/mountId"]
| project Computer, tostring(Mount), ["Free MB"]=round(Val)
) on Computer, Mount
| project Computer, Mount, ["Average % Free Space"], ["Free MB"]
| summarize ["Average Free Megabytes"]=avg(["Free MB"]) by Computer, Mount, ["Average % Free Space"]
| project Computer, Mount, ['Average % Free Space'], round(['Average Free Megabytes'])
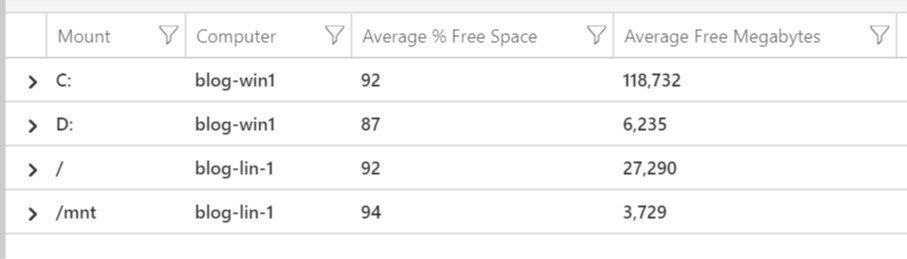
And here is the output
CONCLUSION
While this was really cool joining the same table on different values to view disk space usage on two separate counter names, just imagine what you could do if you joined CPU and Memory usage? Or CPU and Network usage? The possibilities are many and provide another way to view telemetry in a way that fits your needs. The awesome thing about Log Analytics is you will take these examples and create something entirely your own that is a view totally different from mine. How cool is that?!
Pro tip: If you have an awesome query, click save, give it a name and it’ll not be forgotten.

Photo by Jackman Chiu on Unsplash
{kind=link}